
The speed of technological advancement and the development of high-throughput screening in recent years means a lot of biological investigations now result in large volumes of data. Biologists are often not experts in statistical or computational methods, so that’s where statisticians come in, such as Associate Professor Jean Yang from the University of Sydney. Her work focuses on developing methods for analysing large amounts of data to help biologists answer their questions of interest.
Last week Associate Professor Yang spoke at Macquarie University about a statistical technique to help biologists identify micro RNAs and their messenger RNA (mRNA) targets. Knowing if miRNAs are implicated in diseases is important for understanding disease mechanisms and in drug development (Goktug et al. 2013). To be able to explore how these collaborations work and the statistical method, a little background about miRNAs is necessary.
DNA is transcribed into mRNA, which is then translated into protein. Proteins create the observable characteristics of organisms (the phenotype). Micro RNAs (miRNAs) are small pieces of RNA about 22 nucleotides long which bind onto mRNA through complementary base pairing (Ambros 2004). Binding of miRNAs to mRNA can stop the translation of proteins. The machinery in the cell that ‘reads’ the mRNA and converts the message into proteins cannot get past the section where the miRNA is bound so a functional protein cannot be made (Bartel 2004; see Figure 1).
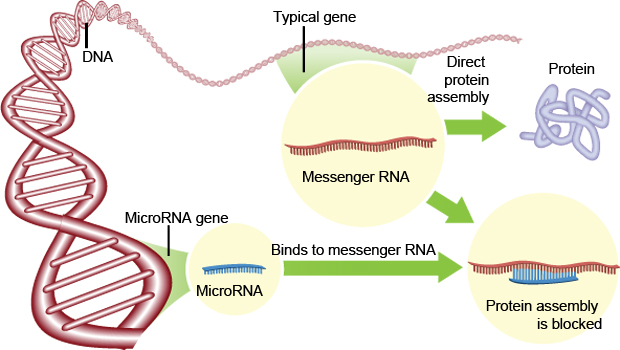
Figure 1. Process of how miRNAs can reduce the production of proteins in a cell
(Image: Steve Karp, Discover Magazine)
MiRNAs are relatively new to science – they were discovered in the 1990s and research implicating miRNAs in diseases has emerged since 2001 (Bartel 2004). Scientists found when there are more miRNAs present (they are upregulated) they can reduce the translation of mRNA into protein (Ambros 2004). This is referred to as downregulation of mRNA (shown with red arrows in Figure 2 below). This downregulation leads to a reduction in the phenotype.
An example of such a cascade is a change in the regulation of tumor suppressor genes. These genes are expressed all the time in cells and this prevents tumors from forming. Upregulation of specific miRNAs that target tumor suppressor genes can reduce the expression of these genes (less mRNA translated into protein). As the tumor suppression mechanism is now less effective there is a chance a tumor could form (Shenouda & Alahari 2009).

Figure 2. Inhibitory cascade initiated by upregulation of miRNA
(adapted from image presented by Associate Professor Yang)
[As a side note: I wonder what starts the upregulation of miRNAs? Why are they present at low levels most of the time and then undergo a dramatic upregulation? Is it a genetic trigger or is there something in the environment triggering this change?]
Now we know what miRNAs do in cells, so we can go back to how Associate Professor Yang is using statistics to help biologists. When biologists and statisticians collaborate there are specialised tasks for each person, but both parties need to understand a little (or a lot) of the other person’s work so they can communicate effectively and address the question of interest together.
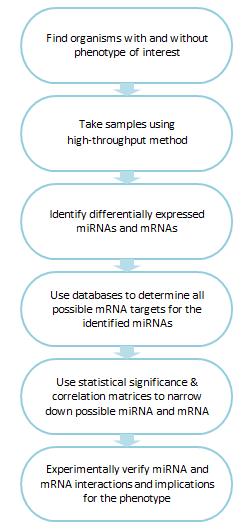
Figure 3. Steps for determining which mRNAs are targets of miRNAs.
Using our miRNA example, the biologist starts by identifying an organism which is showing the phenotype of interest (for example, a disease). Samples are taken from this organism using a high-throughput method (such as a microarray) and the biologist presents the statistician with information on which miRNAs and mRNAs are expressed in the disease state but not in a healthy organism (referred to as differential expression; Jayaswal et al. 2012). At this point the biologist knows there is a mixture of miRNAs and mRNAs present, but the interactions are unknown. Figure 3 outlines the process described below
Using databases, such as TargetScan, the statistician can work out which genes the miRNAs may be targeting and therefore causing the phenotype. TargetScan uses the miRNA nucleotide sequence to find corresponding sequences in mRNA across the whole genome (Witkos et al. 2011). This step doesn’t confer any meaning on these matches; it just presents all possibilities (which can amount to thousands of pairs of miRNAs and mRNAs).
Associate Professor Yang is developing a statistical method, pMimCor, to whittle down the possible pairs of miRNAs and mRNAs to those most likely to be causing the phenotype. The statistician passes this information back to the biologist who can experimentally test the small number of pairs (Jayaswal et al. 2012). The biologist is looking to see if the upregulation of a specific miRNA causes a downregulation in the target mRNA and the disease phenotype.
The method used in this example was only possible due to cooperation between a biologist and a statistician, Associate Professor Yang. Using statistical methods for analysing vast amount of data from high-throughput methods can add value to the work conducted by many types of scientists. Collaborations are ‘very dear to the heart’ of Associate Professor Yang as she knows that cooperation between disciplines can provide an efficient and effective way to answer scientific questions.
Learn more:
Click here for a video lecture about micro RNA by David Bartel, Professor of Biology at MIT.
Ambros V (2004). The functions of animal microRNAs. Nature, 431, 350-355.
Bartel DP (2004). MicroRNAs: Genomics, Biogenesis, Mechanism, and Function. Cell, 116, 281-297.
Goktug AN, Chai SC and Chen T (2013). ‘Data Analysis Approaches in High Throughput Screening’, in HA El-Shemy (ed), Drug Discovery, InTech, DOI: 10.5772/52508.
Jayaswal V, Lutherborrow M and Yang YH (2012). Measures of Association for Identifying MicroRNA-mRNA Pairs of Biological Interest. PLoS One, 7(1), e29612.
Shenouda SK and Alahari SK (2009). MicroRNA function in cancer: oncogene or a tumor suppressor? Cancer Metastasis Review, 28(3-4), 369-378.
Witkos TM, Koscianska E and Krzyzosiak WJ (2011). Practical Aspects of microRNA Target Prediction. Current Molecular Medicine, 11, 93-109.
